
近日,必威BETWAY西汉姆联徐扬团队的三项成果《设计端口缓冲区共享的无损流控方法InfiniFlow支持海量虚拟通道》、《设计Scale-up PIFO系统支撑高速可编程调度》、《设计解耦式DPU架构DistDPU支撑高性价比AI云》被计算机网络领域顶级会议ACM SIGCOMM 2026接收。这也是团队自2023年发表复旦大学首篇 SIGCOMM 长文以来,连续第四年在 SIGCOMM 发表长文,体现了团队在计算机网络领域持续稳定的高水平科研创新能力。
01设计端口缓冲区共享的无损流控方法InfiniFlow支持海量虚拟通道
现代数据中心对网络吞吐与时延提出了更高要求。远程直接内存访问(RDMA)凭借高吞吐、低时延特性,已成为高性能数据中心网络的重要基础。然而,现有RDMA网络普遍采用基于虚拟通道(VC)的逐跳流量控制以保证无损,导致多个数据流共享同一VC时易发生队头阻塞,并引发拥塞扩散。增加VC可以提升流量隔离性,但现有主流流控机制需要为每个VC预留独立缓冲区,导致缓冲区需求随VC数量线性增长,难以支持大规模VC。
针对上述问题,学院徐扬教授团队提出VC缓冲区共享的流控机制InfiniFlow,可在现代商用交换机有限的缓冲区预算下支持上万个VC。研究成果以《InfiniFlow: Decoupling Virtual Channel Scalability from Buffer Requirements in Lossless Datacenter Networks》为题,被计算机网络领域国际顶级会议SIGCOMM 2026接收。
InfiniFlow的核心创新在于:(1)同端口VC缓冲区共享:利用VC速率与缓冲区配额成正比的特性,结合VC聚合速率受限于链路线速的约束,采用同端口VC缓冲区共享架构,解耦端口缓冲区总需求与VC数量的线性关系;(2)基于上游驱动思想的缓冲区管理范式UABD:InfiniFlow突破传统本地式缓冲区管理方式,在上游端口构建下游缓冲区信用值池,使上游调度器能够在发送数据包的同时动态分配缓冲区,实现缓冲区即时分配。在此基础上,研究团队设计了VC缓冲区分配协议BUCP,结合实时下游数据积压反馈,为各VC动态设置信用阈值,提升缓冲区利用效率,实现VC间高效隔离,避免拥塞扩散。
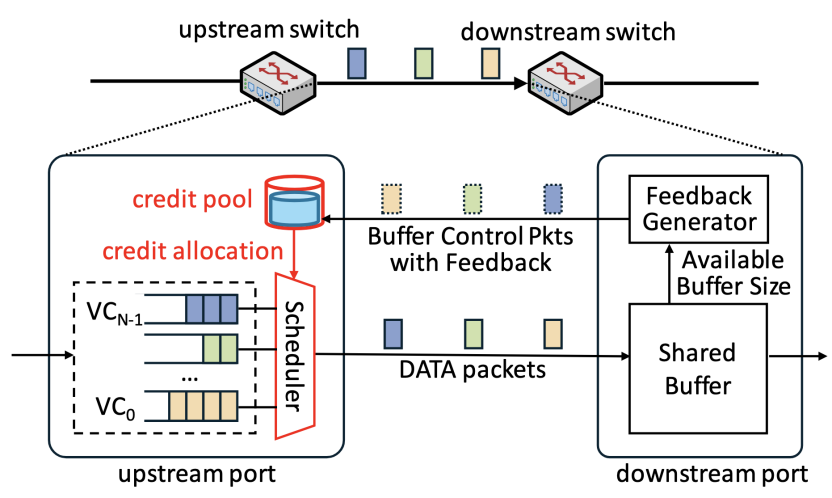
图1 InfiniFlow概述
得益于上述设计,InfiniFlow使端口缓冲区需求不再随VC数量增长,而仅与链路单跳带宽时延积(BDP)相关。研究团队基于Xilinx Alveo U280 FPGA完成了InfiniFlow原型实现,在仅使用401KB片上存储资源的情况下,即可支持超过1.6万个VC并保持100Gbps线速转发,相比主流CBFC和PFC方案,VC扩展能力分别提升512倍和1024倍。NS-3仿真表明,在真实工作负载下,InfiniFlow无需依赖传统端到端速率控制,在流完成时间与流量隔离能力等方面均优于现有逐跳流量控制方法及主流端到端拥塞控制方案。
该研究由博士生田泽瑞、刘森副研究员担任共同第一作者,徐扬教授为通讯作者,并得到国家自然科学基金与国家重点研发计划支持。InfiniFlow突破了RDMA网络中VC数量受限的关键瓶颈,为构建高吞吐、低时延、强隔离能力的新一代数据中心网络提供了重要技术支撑。
02设计Scale-up PIFO系统支撑高速可编程调度
随着数据中心链路速率从400Gbps、800Gbps迈向1.6Tbps,网络设备对数据包调度能力提出了更高要求。数据包调度决定了不同业务流量的转发顺序,是保障服务质量、降低短流完成时间、支持多样化云业务的关键机制。然而,现有商用设备多依赖严格优先级、轮询等固定调度算法,难以灵活适配不同业务需求。近年来,Push-In First-Out(PIFO)被提出作为可编程数据包调度的统一抽象,可通过改变数据包rank计算逻辑,在同一硬件上实现多种调度策略。但在1.6Tbps端口速率下,单个PIFO队列需要在亚纳秒级时间内完成入队和出队操作,现有单队列设计难以满足极高速率网络的处理需求。
针对这一挑战,学院徐扬教授团队提出高速可编程调度系统Scale-up PIFO,通过交错多个并行硬件PIFO队列,实现可编程调度能力的吞吐扩展。相关研究以《Scale-up PIFO: Interleaving Multiple Priority Queues for High Speed Programmable Scheduling》为题,已被计算机网络领域顶级会议ACM SIGCOMM 2026接收。
Scale-up PIFO的核心创新在于提出Rank Range Load Balancing机制,在通过交错多个并行硬件PIFO队列提升吞吐的同时对调度误差进行系统化约束。该机制首先将数据包rank空间划分为多个连续区间,再在每个rank区间内部将数据包均衡分散到多个并行PIFO队列中。由于轮询出队造成的乱序主要来自相近rank的数据包集中进入同一个PIFO队列,Scale-up PIFO通过“按rank分区、区间内均衡”的方式,避免高优先级数据包过度集中,从而将调度误差限制在对应rank区间的排空时间内。与此同时,系统根据流量rank分布的长期统计特征,周期性调整区间边界,使其能够适应真实网络中动态变化且高度偏斜的业务负载。
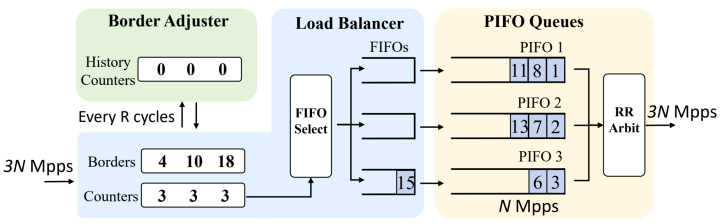
图2 Scale-up PIFO架构
实验结果表明,Scale-up PIFO在实现1.6 Tbps吞吐的同时,可在典型数据中心场景下,相比现有近似PIFO方案将调度误差降低52倍以上,并将短流完成时间缩短45%以上,充分验证了其在提升网络服务质量方面的有效性。
该研究由博士生梅昊担任第一作者,徐扬教授为通讯作者,得到国家自然科学基金和国家重点研发计划项目支持。Scale-up PIFO的提出为下一代高速可编程调度器提供了一条新的扩展路径,也为未来AI数据中心、骨干网络和高性能交换芯片中的流量管理机制提供了重要参考。
03设计解耦式DPU架构DistDPU支撑高性价比AI云
随着大模型训练与推理业务快速发展,云数据中心单服务器网络带宽正迈向Tbps级别。传统方案通常通过堆叠多块DPU提升带宽,成倍增加控制面计算资源和内存资源,导致成本、功耗和运维复杂度显著增加。与此同时,AI业务通常以少量长连接、大流量的“大象流”为主,数据面带宽需求高速增长,而控制面管理压力并未同比例增加,形成了明显的控制面与数据面资源错配问题。
针对这一挑战,学院徐扬教授团队与腾讯云高性能网络产品中心合作,提出解耦式DPU架构DistDPU,通过将传统单体DPU拆分为负责全局编排的Orchestration Module(OM)和负责高速执行的Execution Module(EM),实现控制面资源与数据面带宽的独立扩展。相关研究以《DistDPU: A Disaggregated DPU Architecture for High-Performance and Cost-Efficient AI Clouds》为题,已被计算机网络领域顶级会议ACM SIGCOMM 2026接收。
DistDPU的核心创新在于采用“Brain-Muscle”架构,将复杂云网络控制逻辑集中在OM中,将线速数据处理能力下沉到轻量级EM中。OM负责设备虚拟化编排、网络虚拟化策略生成、RDMA参数配置、密钥管理、监控与故障处理等需求不随带宽线性增长的功能;EM则负责PCIe设备呈现、以太网/RDMA高速处理、网络虚拟化表项匹配与报文转发等关键数据通路功能。通过这种分工,DistDPU能够在保持DPU安全边界和云原生管理语义的同时,仅通过增加低成本EM扩展数据面带宽,避免重复部署昂贵的SoC、内存和完整管理软件栈。
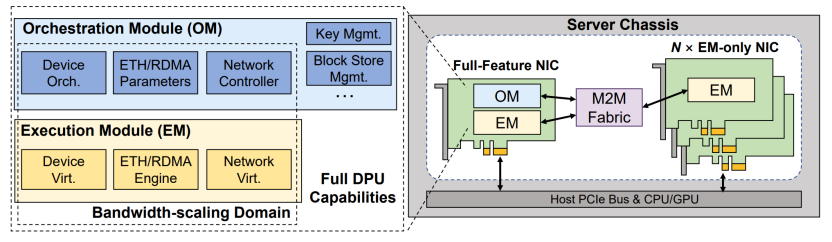
图3 DistDPU架构
真实生产环境显示,DistDPU可将单服务器带宽扩展至最高3.6 Tbps。与堆叠多块DPU方案相比,单节点硬件成本和功耗最高分别降低77.1%和59.3%;同时,在大模型训练和DeepSeek-R1推理任务中,DistDPU能够实现与非虚拟化CX-7集群相近的端到端性能。
该研究由博士生梅昊担任第一作者,徐扬教授为通讯作者,得到国家自然科学基金、国家重点研发计划及复旦-腾讯合作项目支持。DistDPU的提出为AI云网络提供了一种新的DPU扩展范式,也为下一代云数据中心DPU架构设计提供了重要参考。
